关于Lofter图片获取的分析
当我们在Lofter上面寻找自己喜欢的图片的时候,常常会遇到作者启用禁止下载原图的情况,以至于我们只能使用截图大法。
但是这样的方法只能获得和手机屏幕分辨率相同的图片,通常是1920x1080。
况且这样操作非常麻烦,所以我们应该从网站的代码结构着手进行分析。
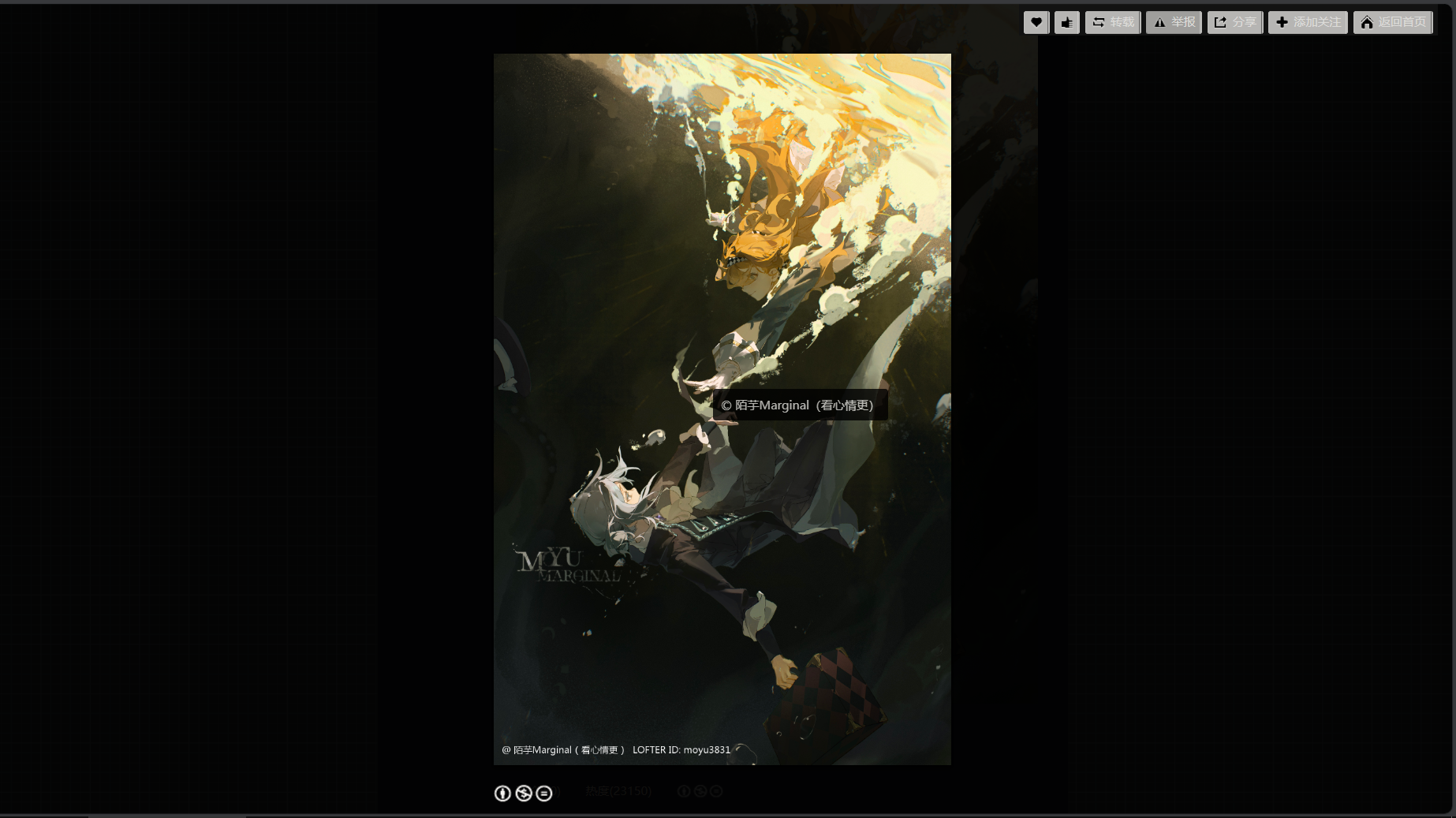
例如这种情况,我们无法通过右键来另存为图片,手机端更不可能长按弹出菜单。
所以我们应该打开F12来看看图片的UR在哪里。
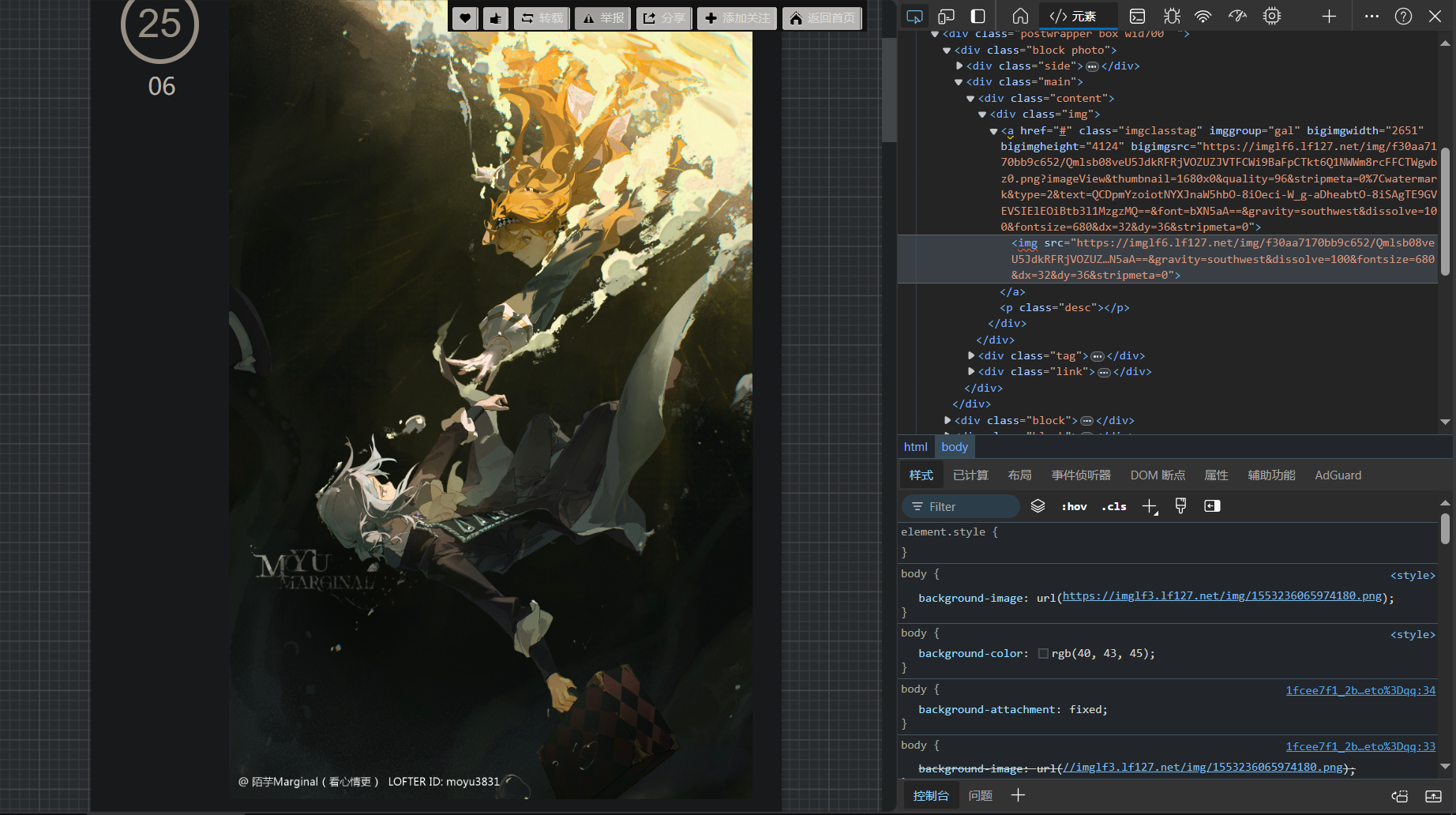
按F12启动开发者模式或者直接图片右键审查元素(大聪明右键都被禁用了)
然后选择审查工具,点击图片。
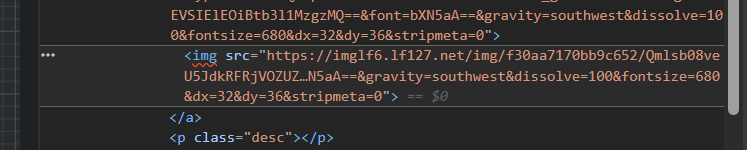
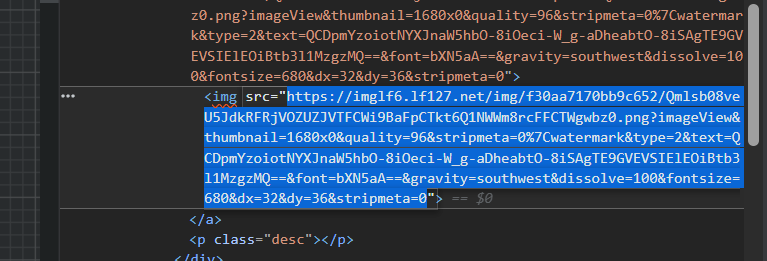
右边提示我们这个图片的相关信息,我们可以很清楚的看出来有一个URL链接,后面还跟了一大串校验符。
把它点开,里面显示出了完整的URL链接。
所以我们复制图片的URL到浏览器地址栏。
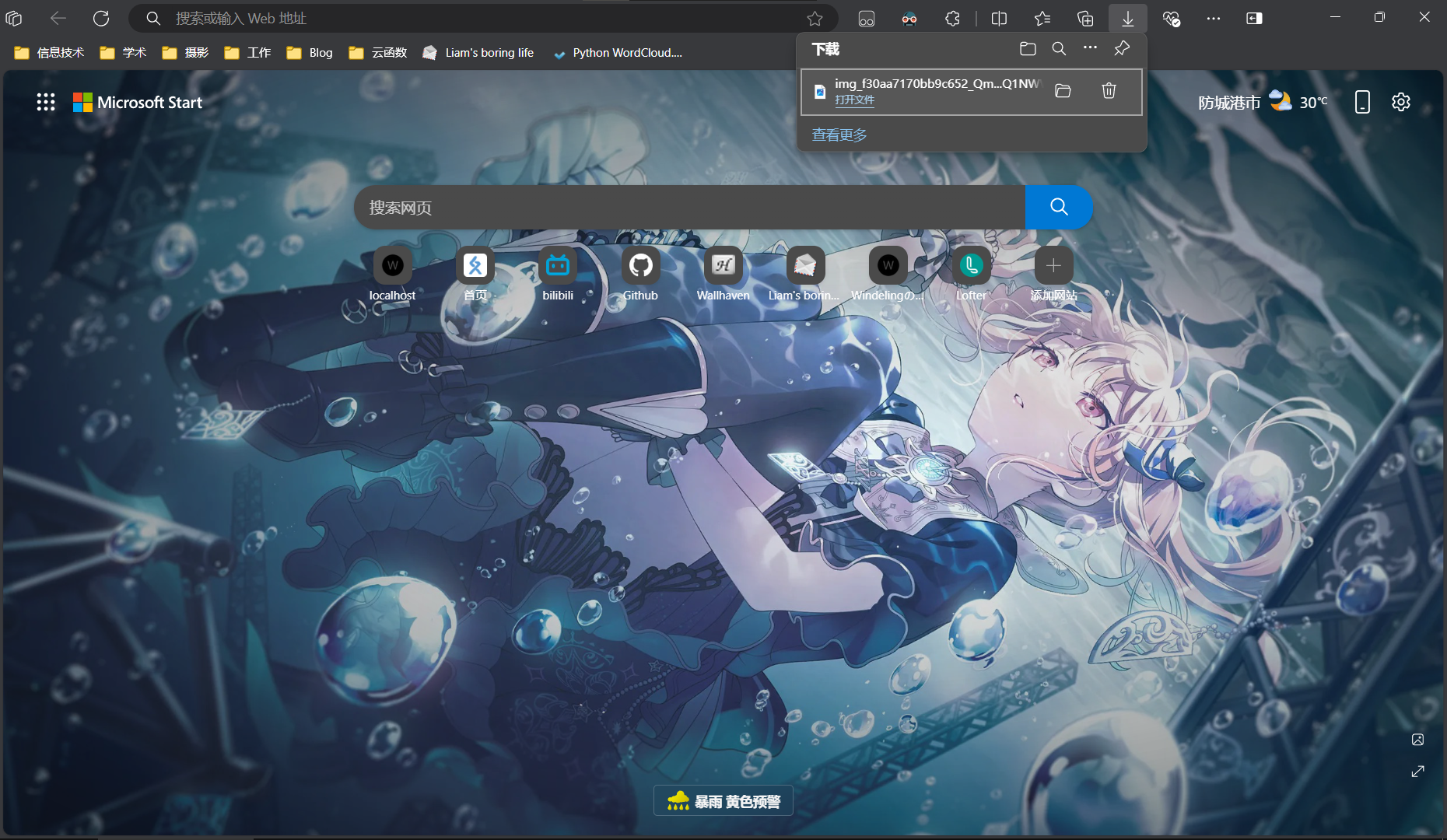
这时候根据浏览器型号,有些浏览器是直接下载文件,有些浏览器是打开原图。
可以看出来Edge浏览器会直接下载图片,我们将其和截图的图片进行比较。
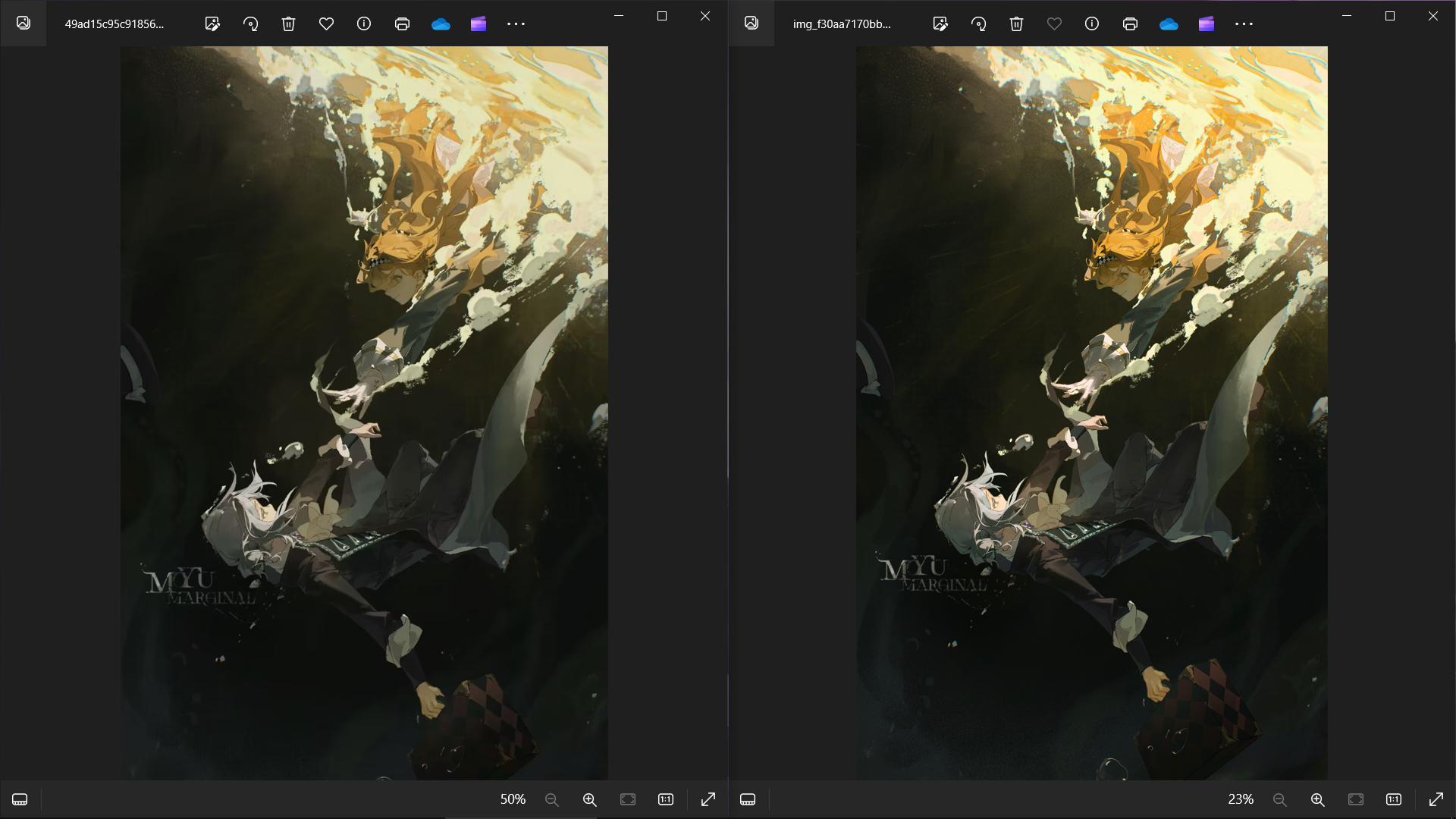
默认大小比较
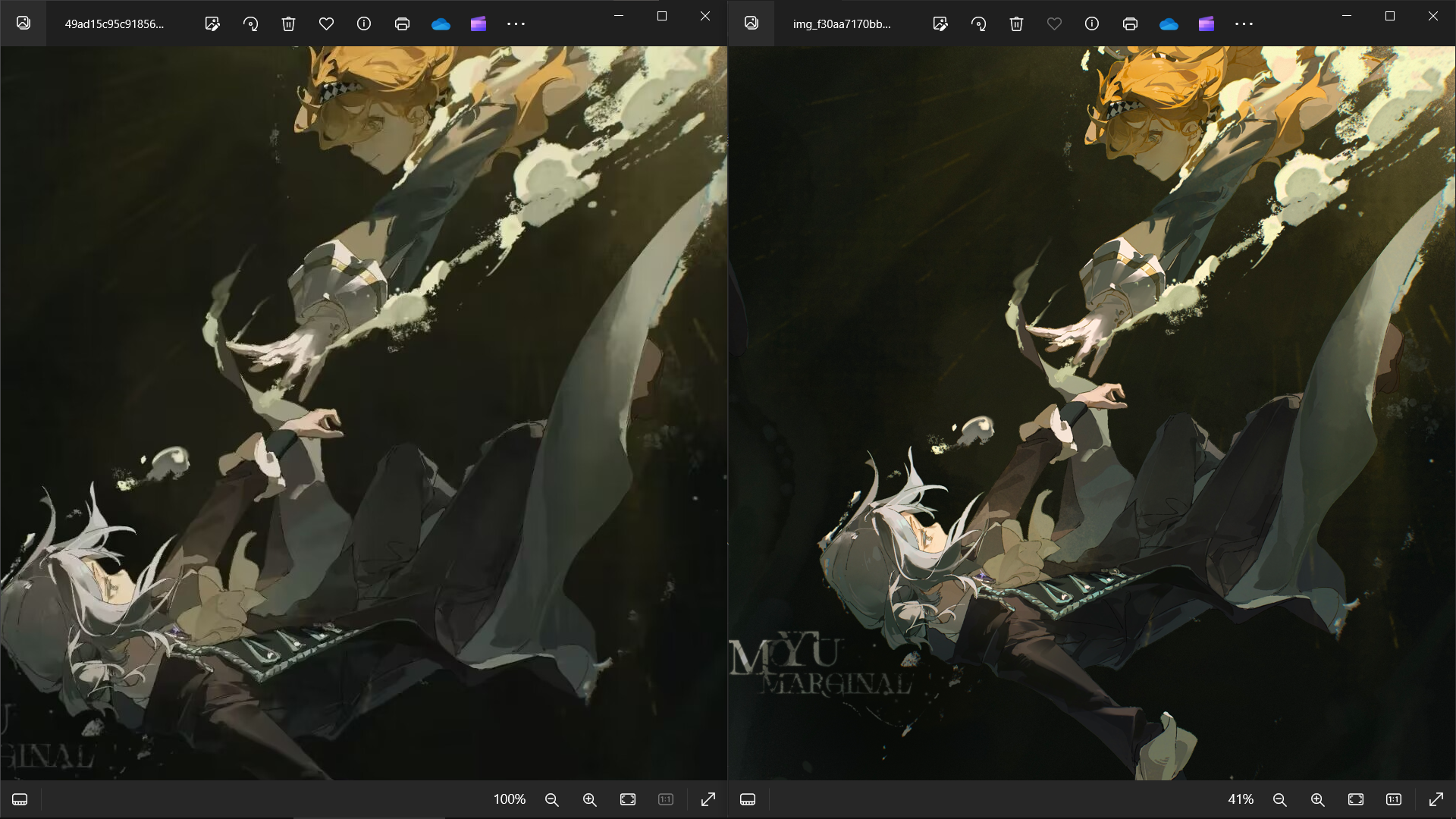
同时基于本身放大滚轮10次
20次
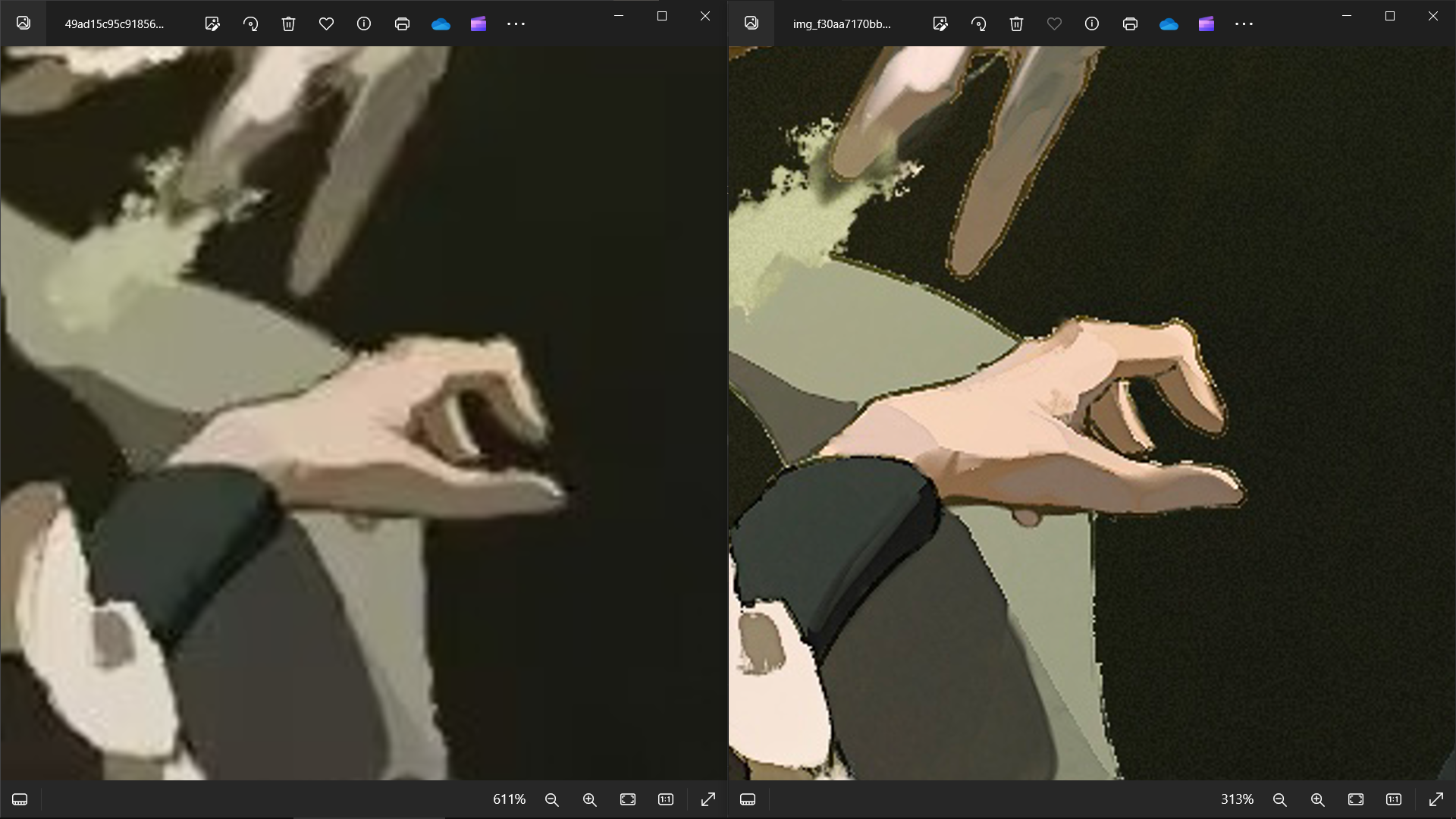
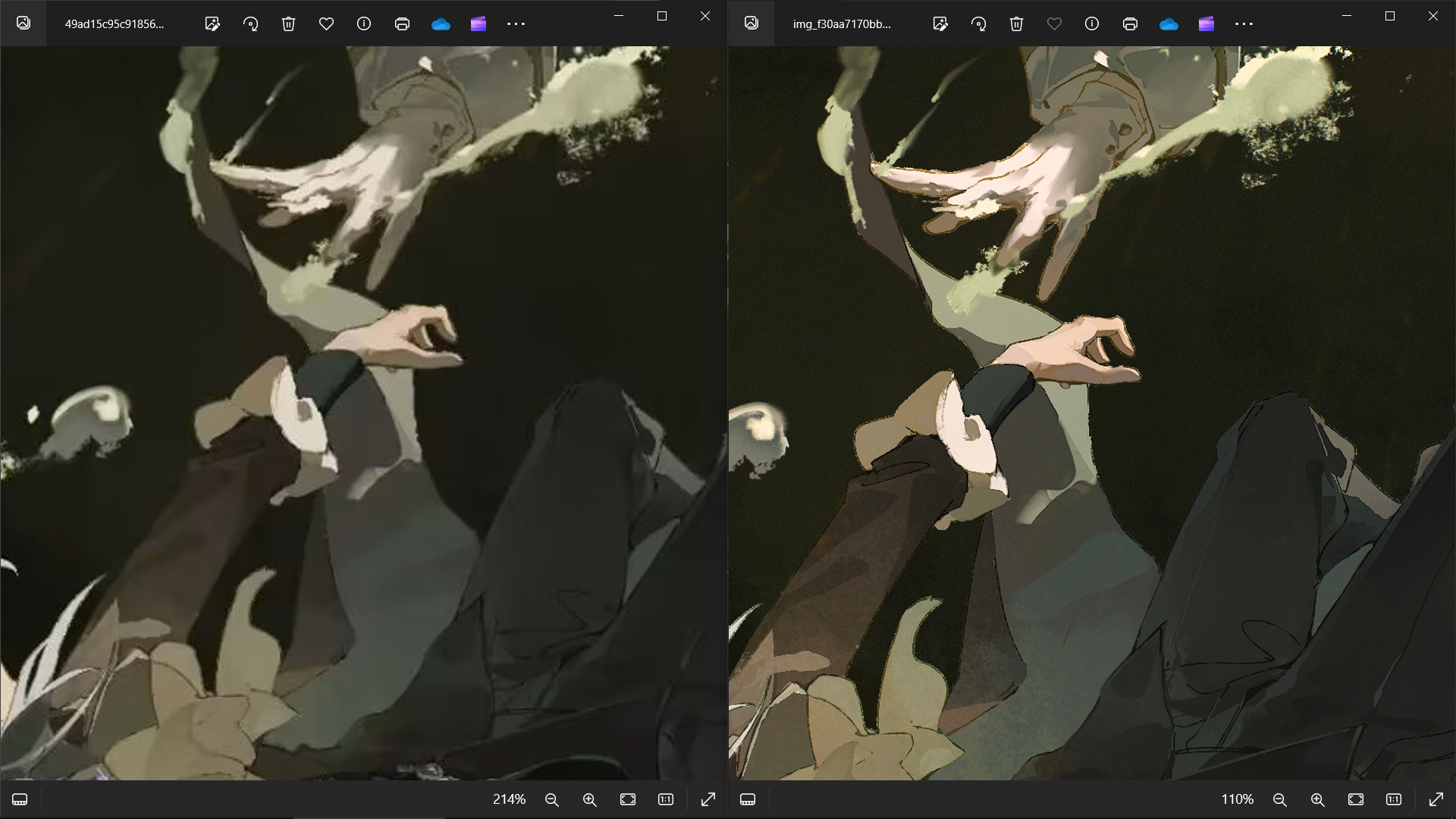
手部细节
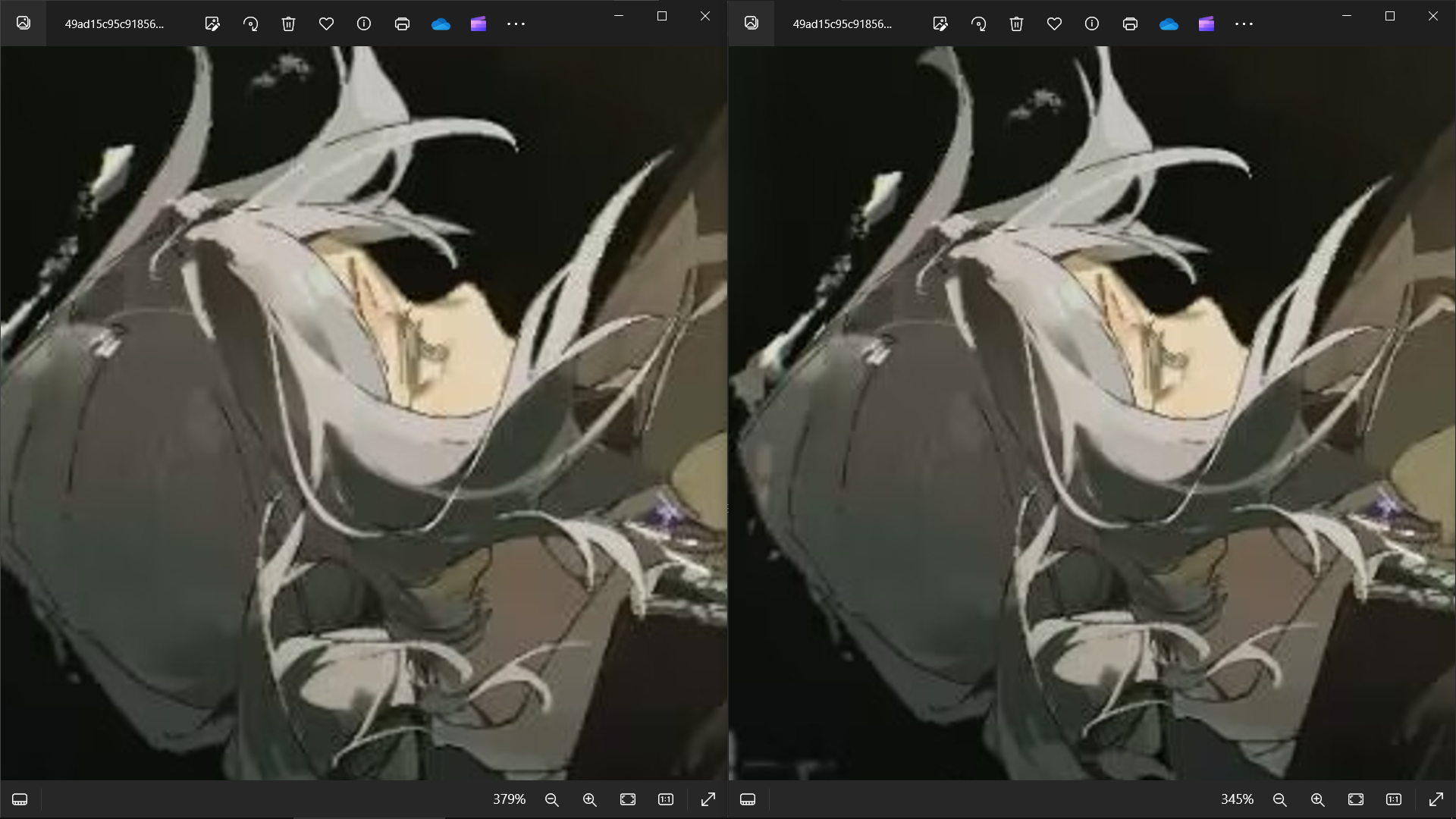
头部细节
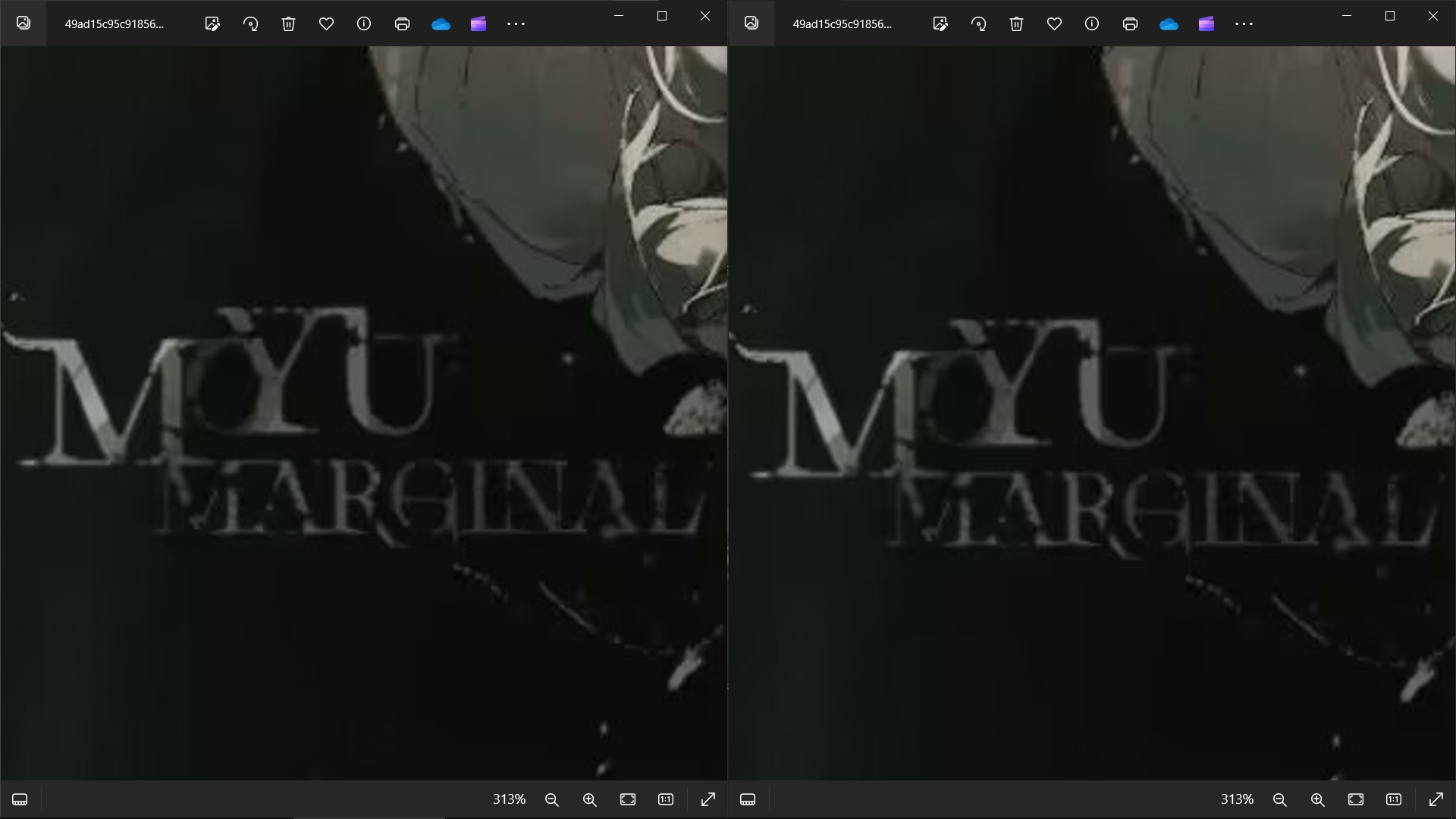
字体细节
看到这里相信大家都可以分辨得出原图和截图了,接下来通过数据对比一下:
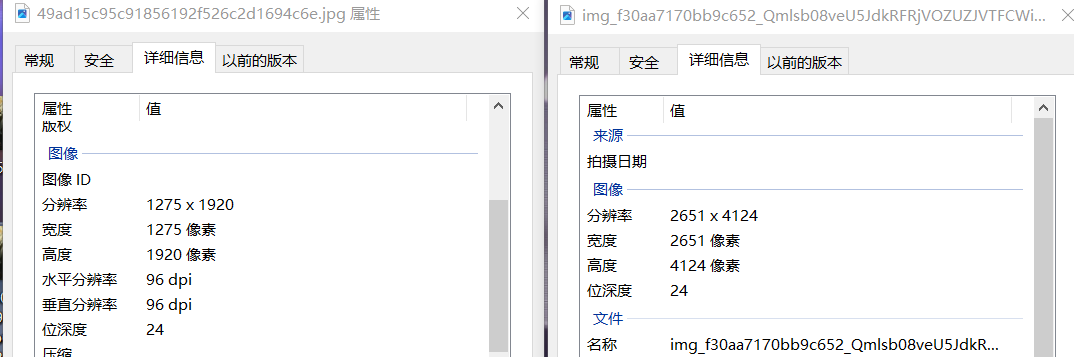
小结:
lofter是通过把图片存放在外链图床中加载的,再禁止lofter页面的右键,达到禁止另存为的效果。
因此找寻到根本的服务器,直接请求图片便可绕过限制解决问题。
声明:
本文纯属学术研究,作者不支持盗版,侵权行为,也希望大家尊重作者的想法。
关于Lofter图片获取的分析
https://blog.windeling.com/20240702d2d5d62b/